blog
What one AI email actually costs
· ai-agents · llm-engineering · roi · cost · observability · pydantic-ai
TLDR
Most AI ROI talk is hand-waving, so here is a traced number from a production agent: one sourced reply to a product email costs about $0.03 in roughly 20 seconds, against roughly $5 and an hours-long wait for a person. Token volume was never the metric — cost per useful outcome is, and almost nobody publishes that from a real system because measuring it means instrumenting the system properly first. The gap between the 95% of AI pilots that show no return and the 5% that work is mostly discipline: measure cost per outcome, cap usage, ground every answer, decline when uncertain.
The question behind the headlines
The horror stories ask whether AI in production is a money pit, but they measure the wrong thing: token volume was never the metric — cost per useful outcome is, and this post publishes one.
If you run a business, the AI story you have been reading lately is a horror story. One company reportedly burned through hundreds of millions of dollars in a single month after turning an AI assistant loose on its staff without limits. The industry even has a name for the behavior that got them there — “tokenmaxxing,” the race to consume as many AI tokens as possible on the theory that more usage means more productivity. And the most-cited research of the year found that roughly 95% of enterprise AI pilots showed no measurable financial return.
So the question on the table for any CIO or CFO is fair and blunt: is AI in production a money pit?
Here is the thing the horror stories miss. Token volume was never the metric. A company can burn a fortune in tokens and get nothing, or spend almost nothing and get real work done. What matters is cost per useful outcome — cost per ticket resolved, per document processed, per email answered. Almost nobody publishes that number from a real production system, because measuring it requires instrumenting the system properly in the first place.
This post publishes one.
MailPilot: a production agent for product email
MailPilot is a live production agent: it reads an incoming product email, searches a knowledge base, and replies with a sourced answer in under a minute — or declines rather than guess.
MailPilot is a production AI agent I built end to end. It reads an incoming business email, searches a knowledge base of product documentation, and replies with a sourced answer in under a minute. If the question is about something not in its knowledge base, it declines and says so rather than guessing. You can email it yourself — it is a live system, not a demo video.
The scenario is a common one: a customer or prospect emails a detailed product question (“what is the permeate flow rate and motor rating for model X?”), and someone on your team has to find the answer in the documentation and write a sourced reply. It maps cleanly onto pre-sales support, RFP responses, and tier-one customer questions. The same pattern generalizes to other high-volume, lookup-heavy work, but the numbers here are measured on this one.
Measured cost: about $0.03 in 20 seconds
Every model call is traced, and answering one fresh, sourced product question costs about $0.03 in roughly 20 seconds — operating cost, not build cost.
Every model call MailPilot makes is traced. The cost of answering one fresh product question, grounded in the documentation and sent back to the customer, is about $0.03, in roughly 20 seconds.
That is the operating cost — the cost to run one email through the system. It is not the cost to build the system; more on that below.
The risk/reward, in numbers you can check
Against a knowledgeable person at a $40/hour loaded rate, the same sourced reply runs about $5 and takes hours — more than a 100× difference in cost, and hours-to-seconds in speed.
The honest comparison is against what answering that same email costs today. Assume a knowledgeable person at a loaded rate of $40/hour. Answering one sourced spec question means reading it, finding the right model in the documentation, and writing the reply — call it 7 minutes once you account for lookup time and the occasional correction. That is around $5 per email, and the customer waits hours for it.
| MailPilot (measured) | A person (assumption) | |
|---|---|---|
| Cost per sourced reply | ~$0.03 | ~$5.00 |
| Response time | ~20 seconds | hours |
| Out-of-scope questions | declines, no guessing | varies |
| At 1,000 emails / month | ~$30 | ~$5,000 |
That is more than a 100× difference in cost, and hours-to-seconds in speed.
The point is not “replace people.” You cannot fire 1/100th of an employee, and a CFO knows it. The point is that a category of repetitive, lookup-heavy email stops consuming thousands of dollars of skilled time each month and gets answered instantly and consistently — freeing that person for work that actually needs them.
Brand and liability, not the token bill
The real exposure is brand and liability, not budget: an agent confidently inventing a spec and sending it over your name — so every answer is grounded in a cited source, declined when out of scope, and measured rather than asserted.
The real risk with AI email is not cost. It is an agent confidently inventing a spec, a price, or a model number and sending it to a customer over your name. That is a brand and liability problem, not a budget line.
This is the part most pilots skip, and it is where the engineering discipline lives. MailPilot is built to ground every answer in a source document and to cite the file it used, so any answer can be checked against the original. When a question falls outside its knowledge base, it is built to decline rather than improvise.
That behavior is measured, not asserted. Over the last 4 days of production traffic MailPilot answered 131 inbound product questions: every reply cited a source document, none was sent without one, and all 131 runs completed cleanly. Under bursts of concurrent traffic the agent hit 30 transient tool errors across 658 tool calls (~4.6% per-call), and every one of the 131 replies still went out — the system retried through the errors and nothing crashed. I am not going to claim an AI is never wrong. I am going to claim this one refuses to invent facts when it lacks a source, and that the claim is checkable in the logs.
Why most AI spend fails, and what makes the difference
What separates the 5% that work from the 95% that don’t is discipline, not the model: measure cost per outcome, cap usage, instrument every call, and ground answers so the system fails safely.
The 95% of pilots that show no return tend to share a pattern: nobody measured the cost per outcome, nobody capped usage, nobody instrumented what the system was actually doing, and nobody designed it to fail safely. They measured token volume, watched the bill climb, and could not connect the spend to value.
The disciplined version is the opposite, and none of it is exotic. Measure cost per outcome. Cap usage so a bug cannot run up a fortune overnight. Instrument every call so you can see where the money goes. Ground answers in real sources and decline when uncertain. That is the difference between the 95% and the 5% — and it is mostly a question of how the system is built, not which model it uses.
Build cost is a separate line from operating cost
Operating cost and build cost are different lines: the $0.03 runs one email, while the retrieval, grounding, guardrails, and scale-to-zero deploy are the one-time investment — hiding that is the kind of ROI claim the hype cycle earned its skepticism for.
The $0.03 is operating cost. Building a production agent — the retrieval, the grounding, the guardrails, the observability, the deployment that scales to zero when idle so you are not paying for it overnight — is the one-time investment. That is the work I do. I am stating the distinction plainly because an ROI number that hides the build cost is exactly the kind of claim the AI hype cycle has earned its skepticism for.
Caveats on the $0.03 and $5 figures
The honest caveats: $0.03 is a fresh question, mid-thread replies cost more because history is re-sent (median ~$0.15, p90 ~$0.24 across 131 production replies), and the $5 human figure is my assumption for you to substitute your own.
So you can weigh this properly: the $0.03 figure is the cost of a fresh question; an ongoing back-and-forth thread costs more, because the conversation history is re-sent each turn. Across 131 production replies over the last 4 days the median per-email cost was ~$0.15 and the p90 was ~$0.24, because most of that traffic is mid-thread, not fresh. The $5 human figure is my assumption, laid out above so you can substitute your own.
If you are evaluating whether AI can do real work in your business without becoming a money pit, that is precisely the question I build for, and measure. If you want to see the cost-per-outcome math on a workflow in your own operation, book a call.
For technical reviewers
The number is read from OpenTelemetry traces in Logfire.
Each agent run is a Pydantic AI invoke_agent span;
per-call cost and token usage come from the gen_ai.usage.* and operation.cost attributes,
summed over the tool-use loop
(search the knowledge base → read the source document → compose and send the reply).
A single fresh in-scope question runs ~17K input tokens —
most of it system prompt, tool definitions, and the retrieved source document,
with about half served from the prompt cache —
and a few hundred output tokens.
The per-email cost scales with thread length: as a conversation accumulates history, each turn re-sends it, so input tokens (and cost) climb. Across 131 production runs in the last 4 days, per-email cost ranged from ~$0.016 on the cheapest fresh question to ~$0.37 at the heaviest observed thread (~278K input tokens, deep conversation history, 29 tool calls). The fresh-thread average held at ~$0.03; the median across all threads, including long ones, was ~$0.15. The representative figure for the “customer asks a question, gets an answer” scenario is the fresh-thread cost; the ramp is a lever (history truncation and summarization) rather than a fixed cost.
The agent, the smoke-test harness, and the grounding logic are on GitHub: github.com/kborovik/mailpilot.
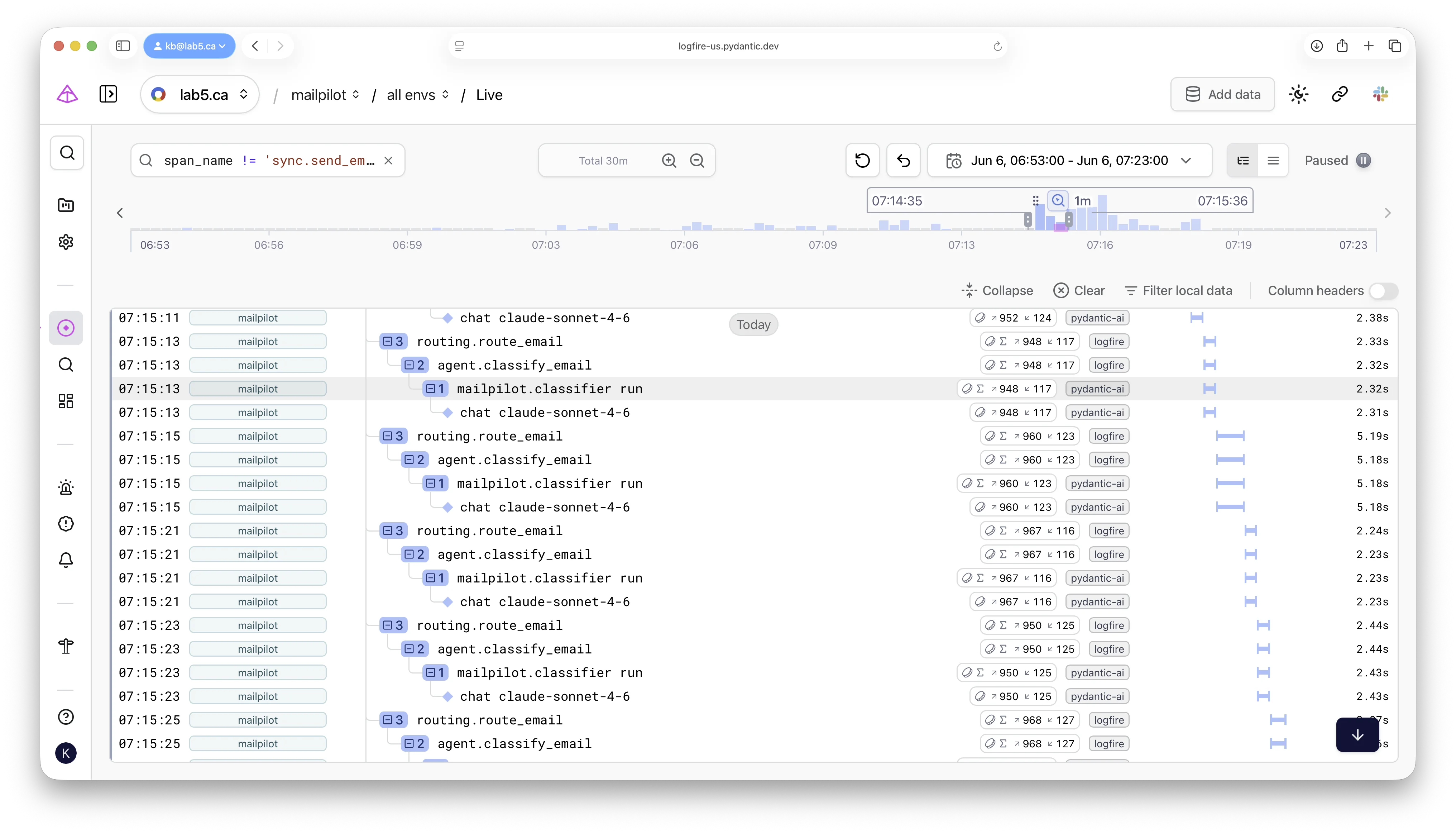
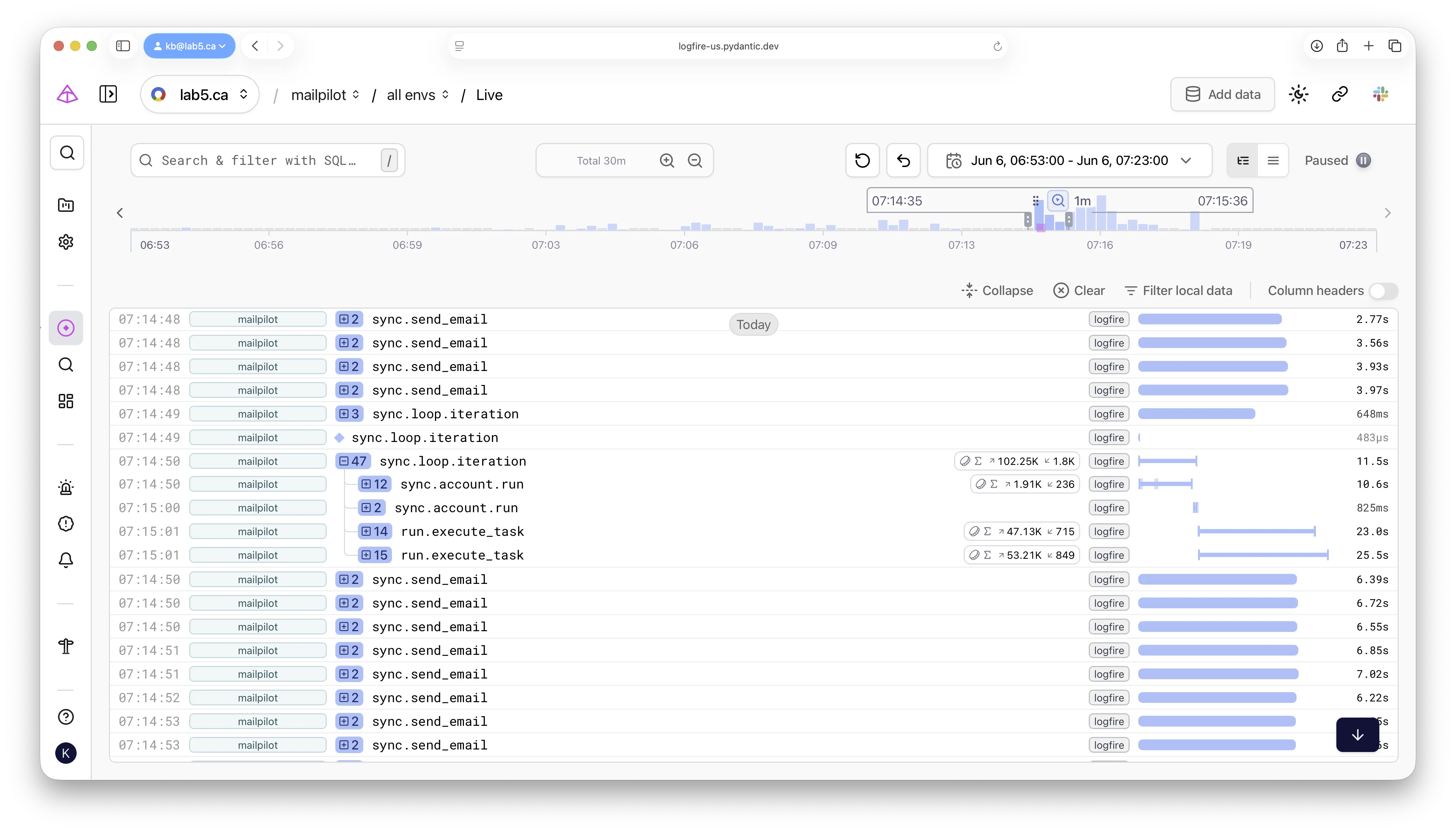
Trace screenshots
The Logfire timeline below lists successive MailPilot email-handling spans —
sync.send_email, sync.loop.iteration, run.account.run, run.execute_task —
with per-span duration down the right column.
Drilling into a single email-handling run opens the span tree —
routing.route_email calls agent.classify_email,
which calls mailpilot.classifier run,
which calls the underlying chat claude-sonnet-4-6 LLM.
Each chat row shows input and output token counts,
which is the surface the per-email cost figure is computed from.